|
667| 0
|
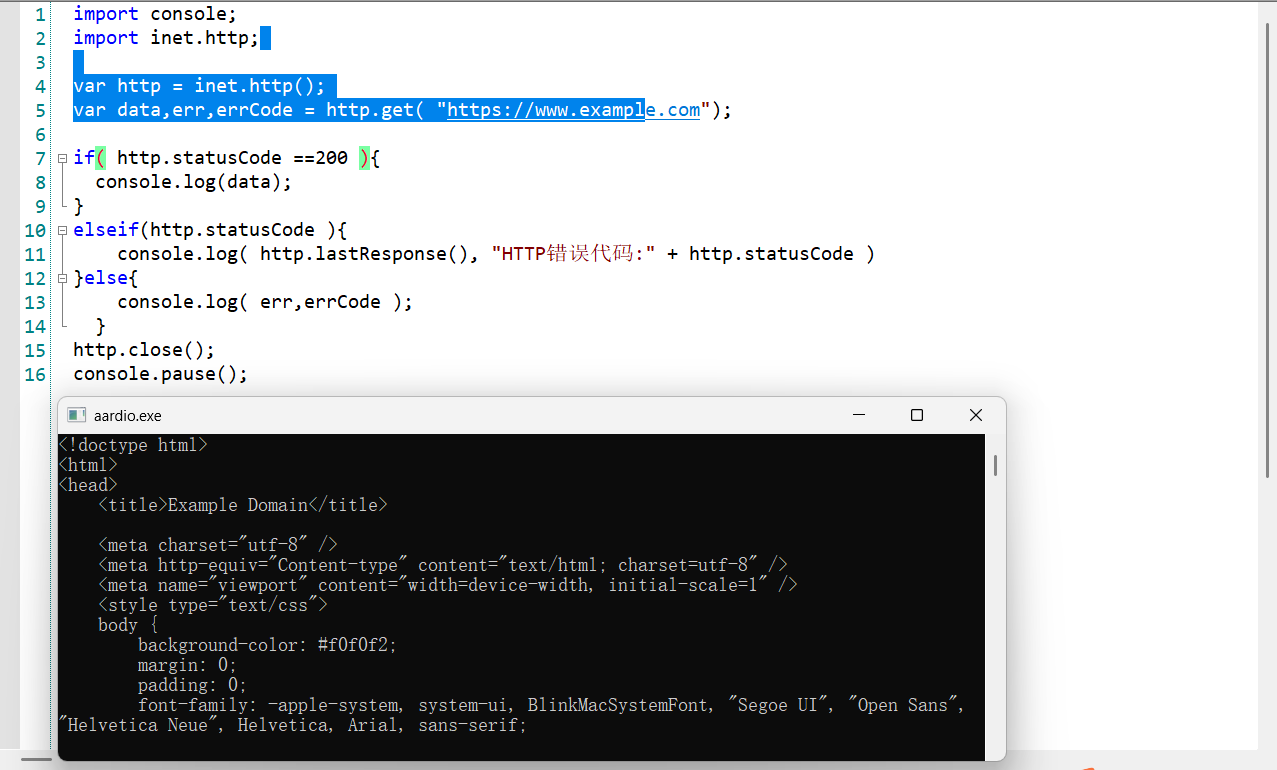
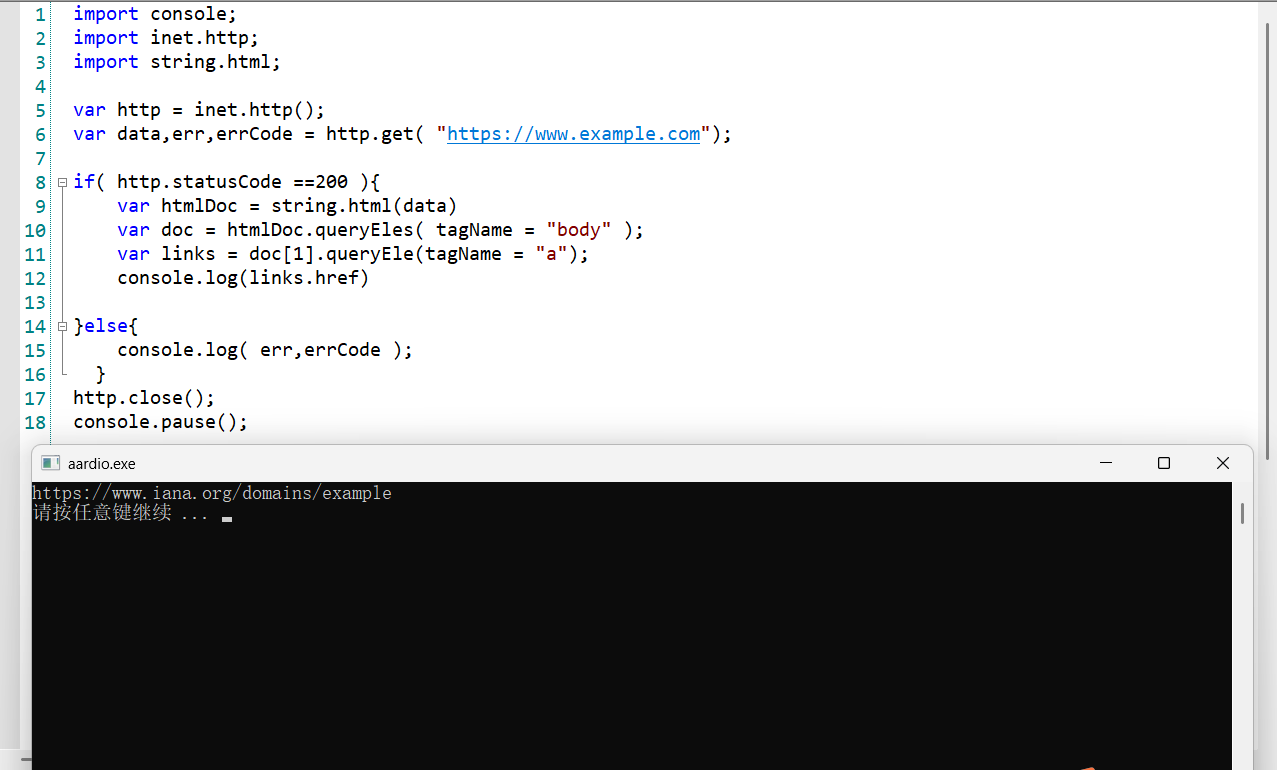
[心得] aardio简单网页爬虫 |
|
非业余 - aardio 编程语言 - 非官方问答社区 - 免责声明
非业余(bbs.feiyeyu.com)所讨论的技术及相关工具源码,仅限用于研究学习,皆在提高软件产品的安全性,严禁用于不良动机。任何个人、团体、组织不得将其用于非法目的,否则,一切后果自行承担。非业余(bbs.feiyeyu.com)不承担任何因为技术滥用所产生的连带责任。非业余(bbs.feiyeyu.com)内容源于网络,版权争议与本站无关。您必须在下载后的24个小时之内,从您的电脑中彻底删除。如有侵权请邮件或QQ微信与我们联系处理。站长邮箱:my69@vip.qq.com
非业余 - aardio 编程语言 - 非官方问答社区 - 免责声明
风行者三期培训:Aardio+Python+Flutter,1000集课程让你成为全栈开发高手!https://mp.weixin.qq.com/s/_WOoHFtITUyLk2k7BXYGkg
Aardio培训大揭秘,轻松上手打造个人项目!https://mp.weixin.qq.com/s/cr47qhp_Cpz0p57lbbPwug aardio风行者第二期培训班https://mp.weixin.qq.com/s/uB6XHUDnGSk0JlWuiBE9AA aardio风行者第三期培训班https://mp.weixin.qq.com/s/cdZcvFiAWhlYTaSrQGCPvA | ||
Archiver|手机版|小黑屋|非业余 - aardio 编程语言 - 非官方问答社区 知道创宇云防御
GMT+8, 2026-1-11 11:22 , Processed in 0.084548 second(s), 31 queries .
Powered by Discuz! X3.5
© 2001-2025 Discuz! Team.



 发表于 2025-5-12 14:46:01
发表于 2025-5-12 14:46:01